学习MySQL表分区
1 什么是表分区
mysql数据库中的数据以文件的形式存储,默认存放在/mysql/data/目录中。一张表对应着三个文件,.frm文件存放表的结构,.myd文件存放表的数据,.myi文件存放表索引的。
表结构如图:

表的数据过大,.myd.myi就会很大,查找数据就会变的缓慢,这个时候我们就可以利用mysql的分区功能。
表分区:根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。
表分区后的结构如图:
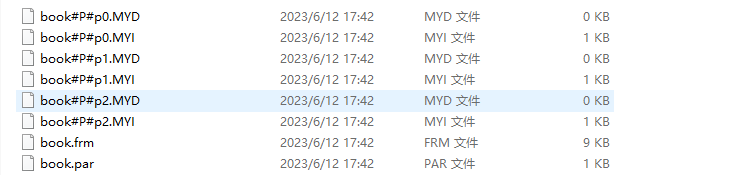
2 表分区与分表的区别
分区和分表完全不是一回事,相信很多初学者容易搞混。
分区逻辑上来说还是一张表,分表则是将一张表分解成了多张不同的表。(此处不多提及,后面会在单出mysql分表)
3 表分区的好处
最直观的好处就是在大数据下,查询速度加快,修改删除数据方便。
具体有哪些好处,可以百度查询。
4 表分区的弊端
在MySQL5.1中,分区表达式必须是整数,或者返回整数的表达式,在MySQL5.5中提供了非整数表达式分区的支持。
其他弊端不做过多说明,同样可以百度查询。
5 MySQL支持的分区类型
5.1 RANGE分区
根据指定的范围条件将数据分配到不同的分区中。例如,可以按照日期范围将数据分区,每个分区包含一段时间内的数据。
5.1.1根据数值范围分区
#创建test表
drop table if exists test;
create table test(
id int not null,
name varchar(10)
)engine=myisam default charset=utf8
partition by range(id)(
partition p0 values less than (3),
partition p1 values less than (6),
partition p2 values less than (9)
);
#查询表所有分区
explain select * from test;
#数据插入
insert into test (id, name) values (1, '张一'),(2, '张二'),(3, '张三'),(4, '张四'),(5, '张五'),(6, '张六'),(7, '张七'),(8, '张八');
#查看指定分区数据
select * from test partition (p0);
#添加分区
alter table test add partition (
partition p3 values less than (12)
);
#拆分分区
alter table test reorganize partition p2 into (
partition p2 values less than (7),
partition p3 values less than (8),
partition p4 values less than (9)
);
#合并分区
alter table test reorganize partition p1,p2 into (partition pp);
alter table test reorganize partition p1,p2 into (
partition p1 value less than (9)
);
#删除指定分区
alter table test drop partition p3;
#删除所有分区,但保留数据
alter table test remove partitioning;为了数据安全,不建议直接添加分区、合并分区,可以如下操作
#创建test_new表
create table test_new(
id int not null,
name varchar(10)
)engine=myisam default charset=utf8
partition by range(id)(
partition p0 values less than (3),
partition p1 values less than (6),
partition p2 values less than (9),
partition p3 values less than maxvalue
);
#将旧表数据插入新表
insert into test_new select * from test;
#重命名旧表
rename table test to test_old;
#重命名新表
rename table test_new to test;不要去碰原始表,而是根据需求创建一个新表,再将原始表数据导入新表,随后再将新表替换为原始表。
特别注意:任何操作前,都要记得备份。
5.1.2根据TIMESTAMP范围分区
drop table if exists test;
create table test(
id int not null,
name varchar(10),
createtime timestamp not null default current_timestamp
)engine=myisam default charset=utf8
partition by range(unix_timestamp(createtime))(
partition p0 values less than (unix_timestamp('2021-01-01 00:00:00')),
partition p1 values less than (unix_timestamp('2022-01-01 00:00:00')),
partition p2 values less than (unix_timestamp('2023-01-01 00:00:00')),
partition p3 values less than maxvalue
);5.1.3根据DATE、DATETIME范围分区
#添加COLUMNS关键字可定义非integer范围及多列范围,不过需要注意COLUMNS括号内只能是列名,不支持函数。
drop table if exists test;
create table test(
id int not null,
name varchar(10),
createtime date not null
)engine=myisam default charset=utf8
partition by range columns(createtime)(
partition p0 values less than ('2021-01-01'),
partition p1 values less than ('2022-01-01'),
partition p2 values less than ('2023-01-01'),
partition p3 values less than maxvalue
);5.1.4根据多列范围分区
drop table if exists test;
create table test(
a int,
b int
)engine=myisam default charset=utf8
partition by range columns(a, b)(
partition p0 values less than (10, 100),
partition p1 values less than (20, 200),
partition p2 values less than (30, 300),
partition p3 values less than (maxvalue, maxvalue)
);5.2 LIST分区
根据列值的列表将数据分配到不同的分区中。例如,可以根据地区或部门名称将数据分区,每个分区包含特定地区或部门的数据。
drop table if exists test;
create table test(
store_id int,
store_name varchar(10)
)engine=myisam default charset=utf8
partition by list(store_id)(
partition pEast values in (1,2,3),
partition pWest values in (4,5,6),
partition pSouth values in (7,8,9),
partition pNorth values in (10,11,12)
);
#与Range分区相同,添加COLUMNS关键字可支持非整数和多列。
#添加分区
alter table test add partition(
partition pCentre values in (13,14,15)
);
#拆分分区
alter table test reorganize partition pEast into (
partition p0 values in (1),
partition p1 values in (2,3)
);
#合并分区
alter table test reorganize partition pEast,pWest into (
partition p0 values in (1,2,3,4,5,6)
);
5.3 HASH分区
根据列值的哈希函数结果将数据均匀地分配到不同的分区中。哈希分区可以确保数据在各个分区中分布均匀,适用于负载平衡和分布式查询。
drop table if exists test;
create table test(
id int
)engine=myisam default charset=utf8
partition by hash(id)
partitions 4;
#Hash括号内只能是整数列或返回确定整数的函数
#如果没有包括一个PARTITIONS子句,那么分区的数量将默认为1
#Hash分区也存在与传统Hash分表一样的问题,可扩展性差。MySQL也提供了一个类似于一致Hash的分区方法-线性Hash分区,只需要在定义分区时添加LINEAR关键字。
drop table if exists test;
create table test(
id int
)engine=myisam default charset=utf8
partition by linear hash(id)
partitions 4;
#优点:增加、删除、合并和拆分分区将变得更加快捷,有利于处理含有极其其大量数据的表。
#缺点:各个分区间数据的分区不大可能均衡。
#减少分区
alter table test coalesce partition 2; #数字代表减掉的分区数
#添加分区
alter table test add partition partitions 3; #数字代表添加的分区数5.4 KEY分区
根据列值的哈希函数或者直接的键值将数据分配到不同的分区中。键分区类似于哈希分区,但可以自定义哈希函数或者直接指定键值进行分区。
drop table if exists test;
create table test(
id int
)engine=myisam default charset=utf8
partition by key(id)
partitions 4;
#与HASH分区不同,创建KEY分区表的时候,可以不指定分区键,默认会选择使用主键或者唯一键作为分区键,没有主键或唯一键,就必须指定分区键。
drop table if exists test;
create table test(
id int primary key
)engine=myisam default charset=utf8
partition by key()
partitions 4;
#减少分区
alter table test coalesce partition 2; #数字代表减掉的分区数
#添加分区
alter table test add partition partitions 3; #数字代表添加的分区数
5.5 子分区
子分区是分区表中每个分区的再次分割,适合保存非常大量的数据,这里不做过多描述,直接上代码示例。
drop table if exists test;
create table test(
id int,
name varchar(10),
createtime date
)engine=myisam default charset=utf8
partition by range(year(createtime))
subpartition by hash(to_days(createtime))
(
partition p0 values less than (2020)(
subpartition s0,
subpartition s1
),
partition p1 values less than (2021)(
subpartition s2,
subpartition s3
),
partition p2 values less than (2022)(
subpartition s4,
subpartition s5
),
partition p3 values less than maxvalue(
subpartition s6,
subpartition s7
)
);
#查询子分区数据
select * from test partition (s1);子分区效果
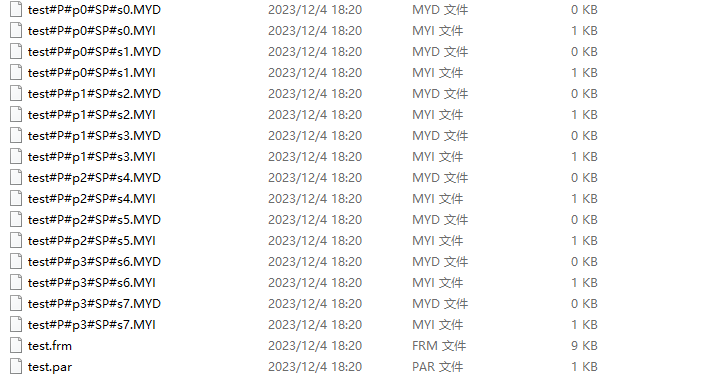
6 分表
这里不做过多描述,只展示分表示例。
#创建表1
create table test_1(
id int not null auto_increment primary key,
name varchar(10),
sex tinyint not null default 0
)engine=myisam default charset=utf8;
#创建表2
create table test_2 like test_1;
#创建总表
create table test_merge(
id int not null auto_increment primary key,
name varchar(10),
sex tinyint not null default 0
)engine=merge union=(test_1,test_2) insert_method=first charset=utf8;
#insert_method=first
#选项分别是:NO、FIRST、LAST,依次代表禁止插入、插入到第一张表、插入到最后一张表。
#插入数据
insert into test_1 (id, name, sex) values (1, '张一', 0);
insert into test_2 (id, name, sex) values (1, '张二', 1);
#查询数据
select * from test_merge where id=1; #只有一条数据
#因为id是primary key,如果在第一个表中查询到记录,则不在后面的表中记录查。如果id并没有定义唯一性约束,则这个查询会得到两条记录。
#添加子表
create table test_3 like test_1;
alter table test_merge union=(test_1,test_2,test_3);
#修改插入位置
alter table test_merge insert_method=last;
insert into test_merge (id, name, sex) values (2, '张二', 1); #数据将插入test_3